

AMD, 3 Kasım 2022’de Radeon RX 7900 serisi ekran kartlarına ait temel detayları açıkladı. Sunumda yeni ekran kartları ve yeni RDNA 3 mimarisi hakkında birtakım bilgiler verildi lakin birçok şey eksikti. Artık RDNA 3 mimarisinin ayrıntılarına derinlemesine bakış atacağız.
Kırmızılılar yeni mimarisiyle birlikte rakibi NVIDIA’ya bir adım daha yaklaştı. En kıymetli ayrıntıya baştan değinecek olursak, çok yongalı yapısı sayesinde GPU tasarımı baştan aşağı değişti.
Daha evvel birçok defa belirttiğimiz üzere, RX 7900 serisinde Navi 31 isimli üst sınıf bir GPU kullanılıyor. Navi 31, Grafik Süreç Kalıbı (GCD) ve Bellek Önbellek Kalıbı (MCD-Memory Cache Dies) olmak üzere iki temel modülden meydana geliyor. AMD’nin Zen 2/3/4 işlemcilerinde benimsenen çiplet dizaynla benzerlikler var, fakat her şey grafik dünyasının gereksinimlerine uyacak biçimde tasarlanmış. Öteki bir deyişle, kırmızı grup işlemci tarafındaki tecrübelerini grafik cephesine aktarmayı başarmış.
Navi 21 GPU özellikleri
AMD Zen Mimarisinin Temeli
AMD, Zen 2 ve sonrasındaki işlemcilerde sistem belleğine bağlanan ve PCIe Express arayüzü, USB temas noktaları ve entegre grafik işlemcisi (Zen 4 ile geldi) üzere üniteleri barındıran bir Giriş/Çıkış Kalıbı (IOD) kullanıyor. İçerisinde birçok farklı ünite barındıran bu yonga, AMD’nin Infinity Fabric teknolojisiyle bir yahut birden fazla CCD’ye (Core Compute Die yahut Core Complex Die) bağlanıyor. Bu CCD’ler ise CPU çekirdeklerini, önbellek ünitesini ve farklı bileşenleri içeriyor.
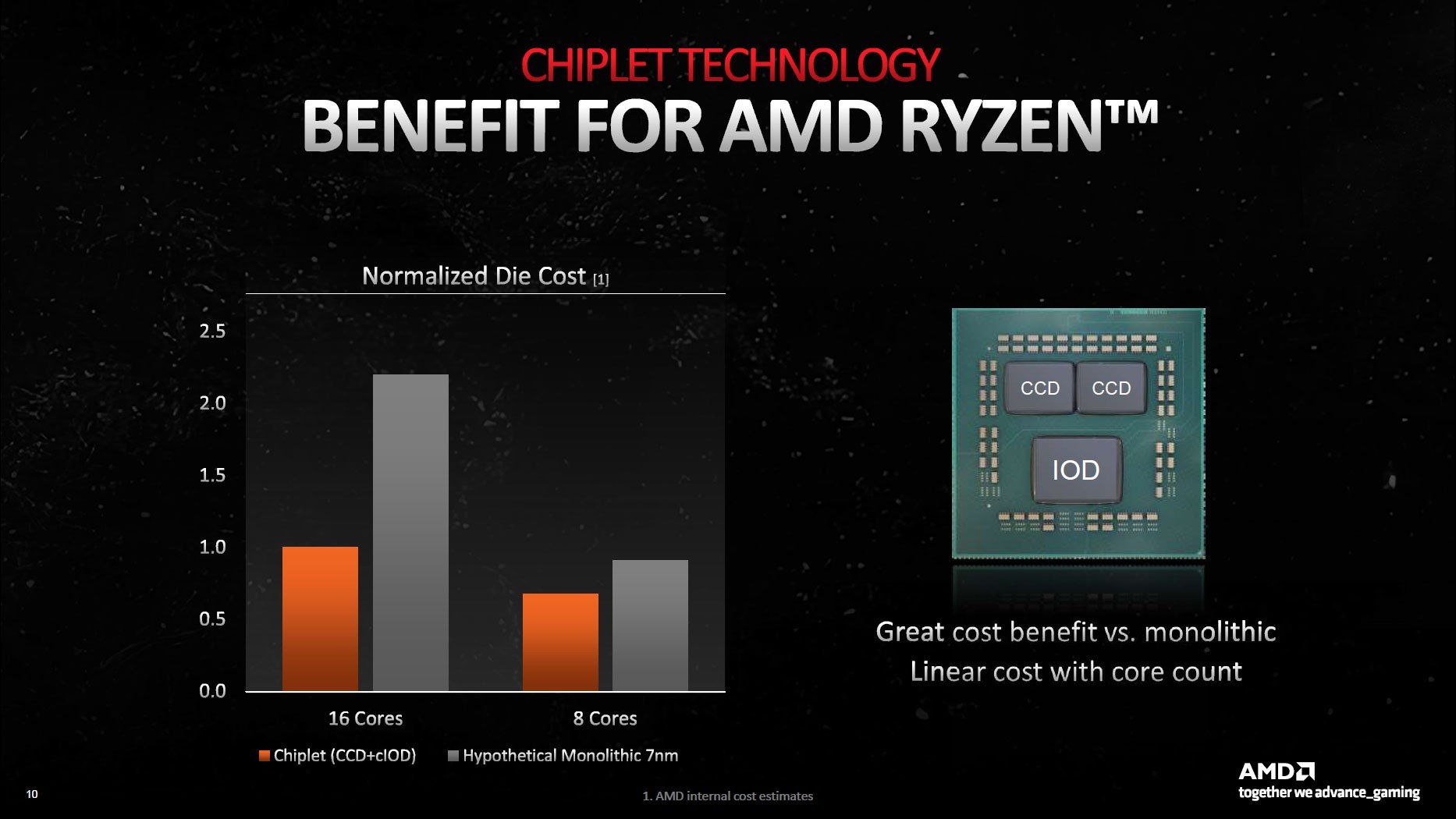
Çekirdekleri içinde barındıran üniteler küçük yapıdayken, IOD yaklaşık 125 mm² (Ryzen 3000) ile 416 125 mm² (EPYC xxx2 nesil) ortasında değişkenlik gösterebiliyor. En son teknolojileri barındıran Zen 4 mimarisinde işler biraz daha değişti. Ryzen 7000 işlemcilerde CCD’ler TSMC N5 (5nm), IOD TSMC N6 (6nm) teknolojisine dayanıyor. Yani bu türlü yapılarda muhtaçlığa ve maliyetlere nazaran kullanılan teknolojiler farklılık gösterebiliyor. Bu da aslında üreticiler için kıymetli bir avantaj.
RDNA 3 Mimarisine Derinlemesine Dalış
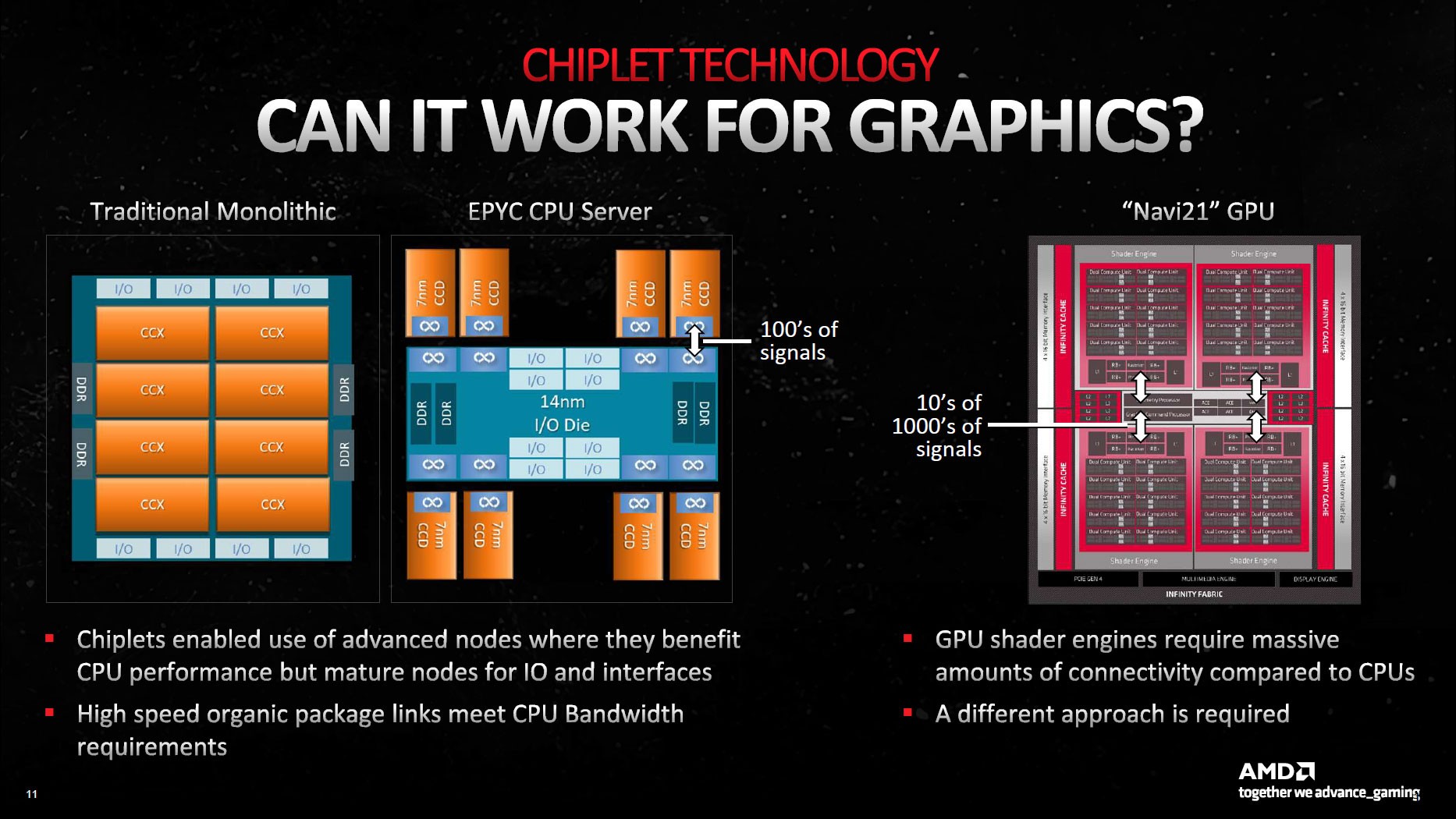
Şimdi gelelim asıl mevzumuza. GPU’lar bildiğiniz üzere farklı ihtiyaçlara sahip ve çok farklı yapıda. Grafik süreç üniteleri, tüm GPU çekirdeklerini beslemek için bol ölçüde bellek bant genişliğine gereksinim duyar. Örneğin, 12 kanallı DDR5 yapılandırmasına sahip devasa EPYC 9654 bile ‘yalnızca’ 460,8 GB/s’ye kadar bant genişliği sunuyor. RTX 4090 ve RTX 3090 Ti üzere ekran kartları ise bu ölçüleri ikiye katlarken 1 TB/sn düzeyinde bant genişliğine sahip.

GPU yongalarının tesirli bir formda çalışması için AMD’nin farklı bir şey yapması gerekiyordu. Şirket mühendisleri tahlili CPU yapılandırmasının tam karşıtını uygulamakta buldu: ana süreç merkezi olarak GCD kullanılırken, bellek denetimcileri ve önbellek birden fazla küçük yongaya yerleştirildi.
GCD ismi verilen ünite görüntü kodlama donanımı, ekran arayüzleri ve PCIe teması üzere öteki temel fonksiyonlarla birlikte Bilgi Süreç Ünitelerini (Compute Unit olarak biliniyor) içinde barındırıyor. Navi 31 GCD, tipik grafik sürece vazifelerini üstlenmek üzere 96 adede kadar CU barındırabiliyor. AMD, GCD’yi gelişmiş Infinity Fabric teknolojileriyle çipin etrafına yayılan MCD’lere ve kartın geri kalanına bağlıyor.
Adından da anlaşılacağı üzere, MCD’ler (bellek kalıpları) büyük L3 önbellek bloklarını (Infinity Cache) ve fizikî GDDR6 bellek arayüzünü içeriyor. Bununla birlikte, MCD’lerin GCD’ye bakan tarafında Infinity Fabric kontakları yer alıyor.
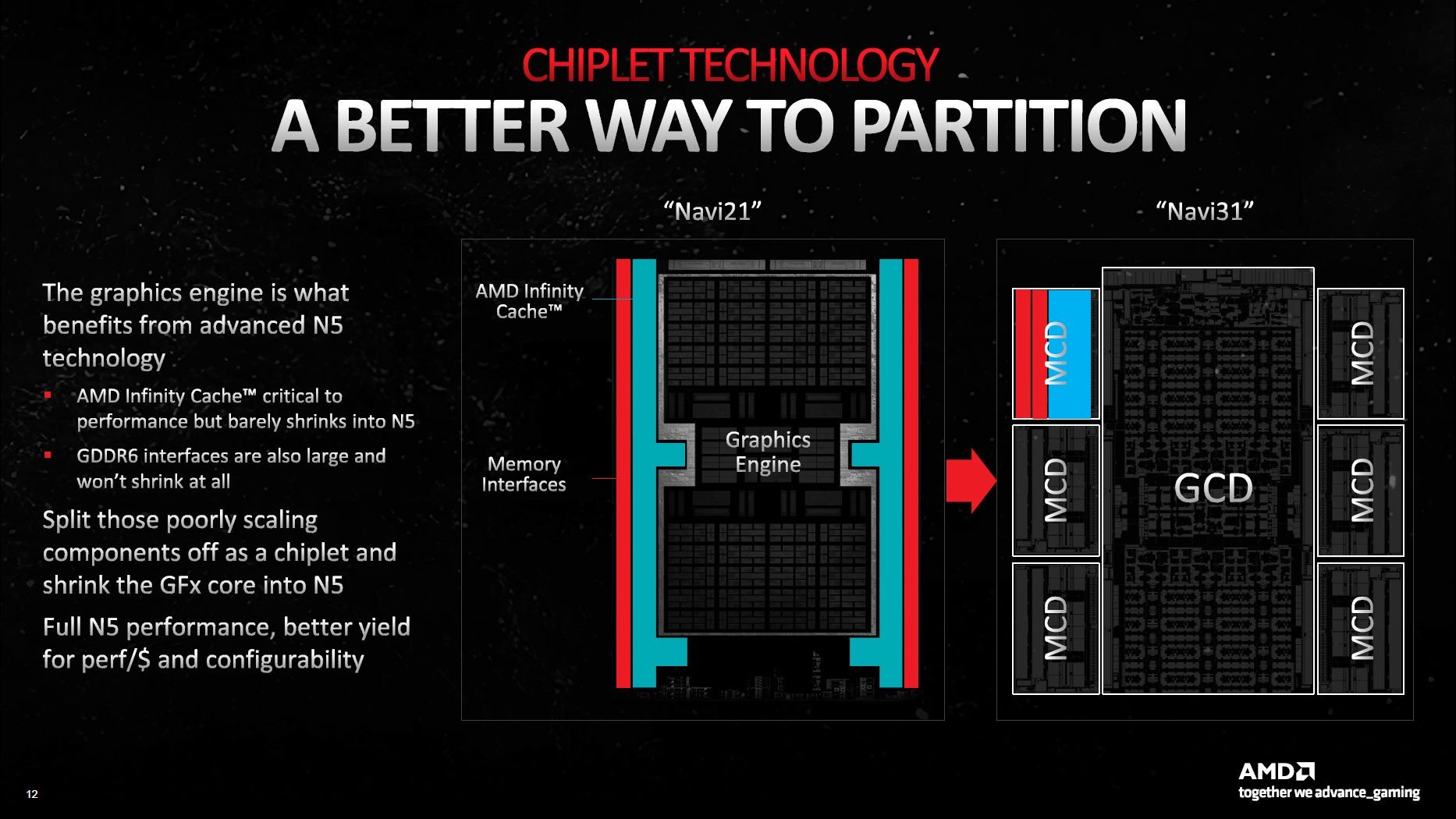
AMD, TSMC’nin N5 teknolojisini kullanarak 300 mm² boyutundaki Navi 31 GCD’ye 45.7 milyar transistör entegre etmeyi başardı. TSMC N6 bandından çıkan 37 mm² boyutundaki MCD’lerde ise 2.05 milyar transistör bulunmakta.
Yüksek Performanslı Orta Temas Teknolojileri: Fanout
Çipler ortası ara irtibat teknolojileri kelam konusu olduğunda birçok kaygı ortaya çıkar. Bu noktada birinci olarak Infinity Fabric irtibatlarının gerektirdiği güç (harici çipler neredeyse her vakit daha fazla güç kullanır) akıllara geliyor. Bunun yanında, temas teknolojisinin verimliliği ve suratı çok kıymetlidir.



Örnek olarak, Zen CPU’larda üretimi nispeten ucuz olan organik bir alt katman orta kesimi var, lakin 1,5 pJ/b (bit başına pikojul) tüketmekte. Emsal bir yaklaşımı 384 bitlik arayüzde kullanmak çok yüksek güç tüketimine yol açacaktı, bu nedenle AMD Navi 31 ile arayüzü geliştirmek için çok gayret harcadı.
Sonuç olarak ortaya “Fanout” orta kontağı olarak isimlendirilen bir tahlil çıktı. Slaytlar her şeyi kapsamlı halde açıklamıyor, fakat sunum görsellerinde CPU’lar (CPU chiplet bandwidth) ve GPU’larda (MCD bandwidth) sunulan bant genişliğinin farkını görebilirsiniz.

AMD RDNA 3 mimarisi.
İşlemcilerde 25 orta temas bulunurken, GPU’lar için kullanılan 50 orta ilişki daha küçük bir alana yerleştiriliyor. Bu da güç ihtiyaçlarını kıymetli ölçüde azaltıyor. AMD, tüm Infinity Fanout irtibatları toplamda 3,5 TB/s aktif bant genişliği sağlarken toplam GPU güç tüketiminin sadece %5’inden azını oluşturduğunu söylüyor.
| Bit başına pikojul (pJ/b) | |
|---|---|
| On-die | 0.1 |
| Foveros | 0.2 |
| EMIB | 0.3 |
| UCIe | 0.25-0.5 |
| Infinity Fabric (Navi 31) | 0.4 |
| TSMC CoWoS | 0.56 |
| Bunch of Wires (BoW) | 0.5-0.7 |
| Infinity Fabric (Zen 4) | ? |
| NVLink-C2C | 1.3 |
| Infinity Fabric (Zen 3) | 1.5 (?) |
Burada değişik bir nokta var: hem GCD hem de MCD’lerdeki Infinity Fabric mantığı yongalarda büyük bir alan kaplıyor. GCD’deki altı Infinity Fabric arayüzü kalıp alanının yaklaşık %9’unu kullanırken, arayüzler MCD’lerdeki toplam kalıp boyutunun yaklaşık %15’ini oluşturuyor.

Infinity Fabric arayüzünü ortadan kaldırıp çipi tek bir kesim halinde TSMC 5nm teknolojiyle inşa etselerdi, GPU boyutu muhtemelen 400-425 mm² ölçülerinde olacaktı. TSMC N5’in maliyeti TSMC N6’dan çok daha yüksek olacak ki AMD çok yongalı dizayna geçiş yapmayı göze almış.
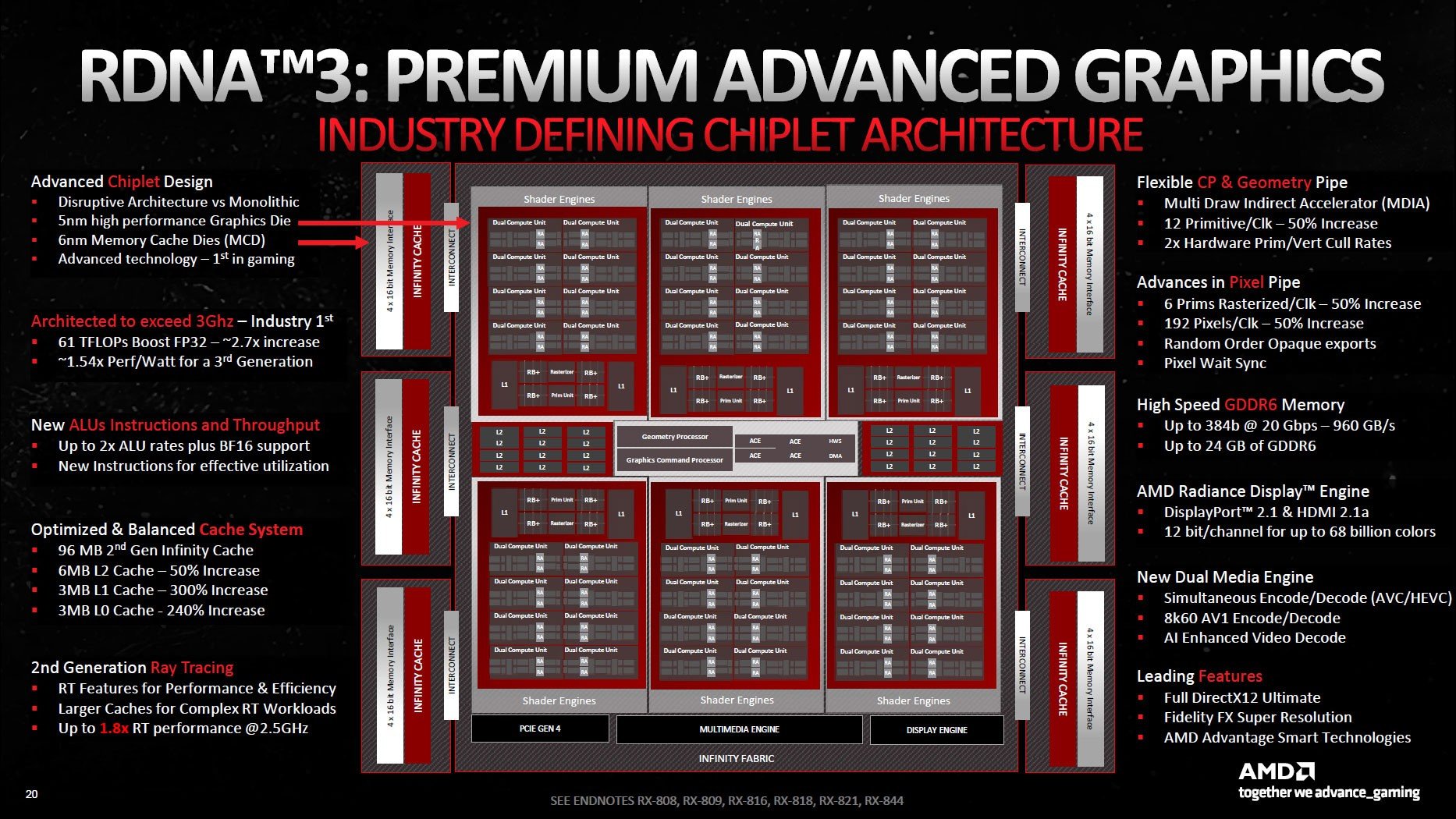
Şimdi GPU’nun çeşitli kısımlarındaki mimari değişikliklere geçelim. Değişimi dört ana başlığa ayırabiliriz: çip dizaynında genel değişiklikler, GPU gölgelendiricilerinde (Stream Processors) geliştirmeler, ışın izleme performansını düzgünleştirmek için güncellemeler ve matris süreç donanımında iyileştirmeler.
İlk başta saat suratları konusunda baş karışıklığı yaratan ayrıntılar vardı. Artık frekans suratlarına ait daha net datalar sağlandı. AMD tarafından sağlanan datalara gelince, RX 7900 XT 2.4 GHz, RX 7900 XTX ise 2.5 GHz yükseltilmiş saat suratına sahip. Lakin şirket RDNA 3 GPU’ların 3.0 GHz sürate ulaşacak formda tasarlandığını söylüyor. Referans saatler 500 MHz kadar daha düşük. Bu noktada kırmızı grubun verimliliği üst seviyeye çıkarmak istediğini düşünüyoruz. MSI ve ASUS üzere üretim ortakları güç limitlerini, voltajları ve saat suratlarını isteğine nazaran yükseltebilir.
AMD’ye nazaran RDNA 3 GPU’lar yarı güç kullanırken RDNA 2 GPU’larla tıpkı frekansa ulaşabiliyor yahut tıpkı gücü kullanırken 1.3 kat daha yüksek frekans sunabiliyor. AMD en uygun tecrübesi sağlamak üzere frekans ve gücü dengelemek istiyor. Bilhassa amiral gemisi RX 7900 XTX’in yüksek güç limitleriyle birlikte yüksek frekanslara eriştiğini görebiliriz.
GPU tasarımcısının dikkat çektiği bir başka nokta ise silikon kullanımını yaklaşık %20 oranında güzelleştirmiş olması. RDNA 2 GPU’larda kart tam yük altındayken bile çipin kesimlerinin sıklıkla boşta kaldığı fonksiyonel üniteler vardı. AMD’nin kelamlarına bakılırsa bu hususta kıymetli geliştirmeler yapıldı.
Hesaplama Üniteleri (CU)
Çiplet tasarımı bir kenara, en kıymetli değişiklikler Hesaplama Üniteleri (Compute Unit-CU) ve Çalışma Kümesi İşlemcileri (Workgroup Processor-WGP) tarafında gerçekleştirildi. Bunlar ortasında L0/L1/L2 önbellek boyutlarında güncellemeler, FP32 ve matris iş yükleri için daha fazla SIMD32 kaydı ve kimi öğeler ortasında daha geniş ve daha süratli arayüzler yer alıyor.
RDNA 3, RDNA yongaların ana yapı taşı haline gelen Hesaplama Üniteleri açısından kıymetli (çiftli süreç birimleri) geliştirmelerle geliyor. Görsellerde RDNA 3 ve RDNA 2 pek farklı görünmeyebilir, lakin zamanlayıcı ve Vektör GPR’leri için birinci blokta “Float / INT / Matrix SIMD32” ve akabinde “Float / Matrix SIMD32” ibarelerini görebilirsiniz. Bu ikinci blok RDNA 3 mimarisinde yeni ve temel olarak kayan nokta randımanının iki katına çıkarılması manasına gelmekte.




Resmiyette her bir Hesaplama Ünitesi’nde 64 Akış İşlemcisi (Stream Processor) yer alıyor. Her şey RDNA 2 mimarisiyle birebir görünebilir, fakat yeni yapılandırma sayesinde aslında toplam 12.288 ALU (Aritmetik Mantık Birimleri-gölgelendirici) elde ediyoruz.
Yeni RDNA 3 birleşik Hesaplama Birimi’nde 64 adet çift çıkışlı (dual-issue) Akış İşlemcisi (GPU gölgelendiricileri) bulunuyor. Bu RDNA 2 mimarisine kıyasla iki katlık bir fark demek. AMD, her SIMD ünitesine farklı iş yükleri gönderebiliyor yahut her ikisinin de tıpkı komut çeşidi üzerinde çalışmasını sağlayabiliyor.
Aslında bu mevzu herkeste baş karışıklığı yaratmıştı. Kimi yerlerde Navi 31’in 6.144, birtakım yerlerde ise 12.288 gölgelendiriciye sahip olduğu söyleniyordu. Baş GPU mimarı ve RDNA 3 dizaynının ardındaki ana isim olan Mike Mantor, bu mevzu sorulduğunda 12.288 sayısını verdi. Lakin AMD sunumlarında düşük sayıları kullanmayı seçiyor.
Önbellek ve Orta Bağlantı
Önbellekler ve sistemin geri kalanı ortasındaki arabirimleri tümünde geliştirmeler yapıldı. Örneğin L0 önbellek 32 KB’a (RDNA 2’nin iki katı), L2 önbellek 6 MB’a (RDNA 2’den 1.5 kat daha büyük) ve L2 önbellek yeniden 6 MB’a (1.5 kat) yükseltildi. Ek olarak, ana süreç üniteleri ile L1 önbellek ortasındaki temas artık 1ç5 kat daha geniş ve saat başına 6144 bayt randıman sağlıyor. Birebir halde, L1 ve L2 önbellek ortasındaki irtibat da 1.5 kat daha geniş (saat başına 3072 bayt).
Infinity Cache olarak da isimlendirilen L3 önbellek Navi 21’e nazaran (96 MB’a karşı 128 MB) küçüldü. Buna karşılık L3’ten L2’ye ilişki artık 2.25 kat daha geniş (saat başına 2304 bayt) ve toplam transfer suratı çok daha yüksek.
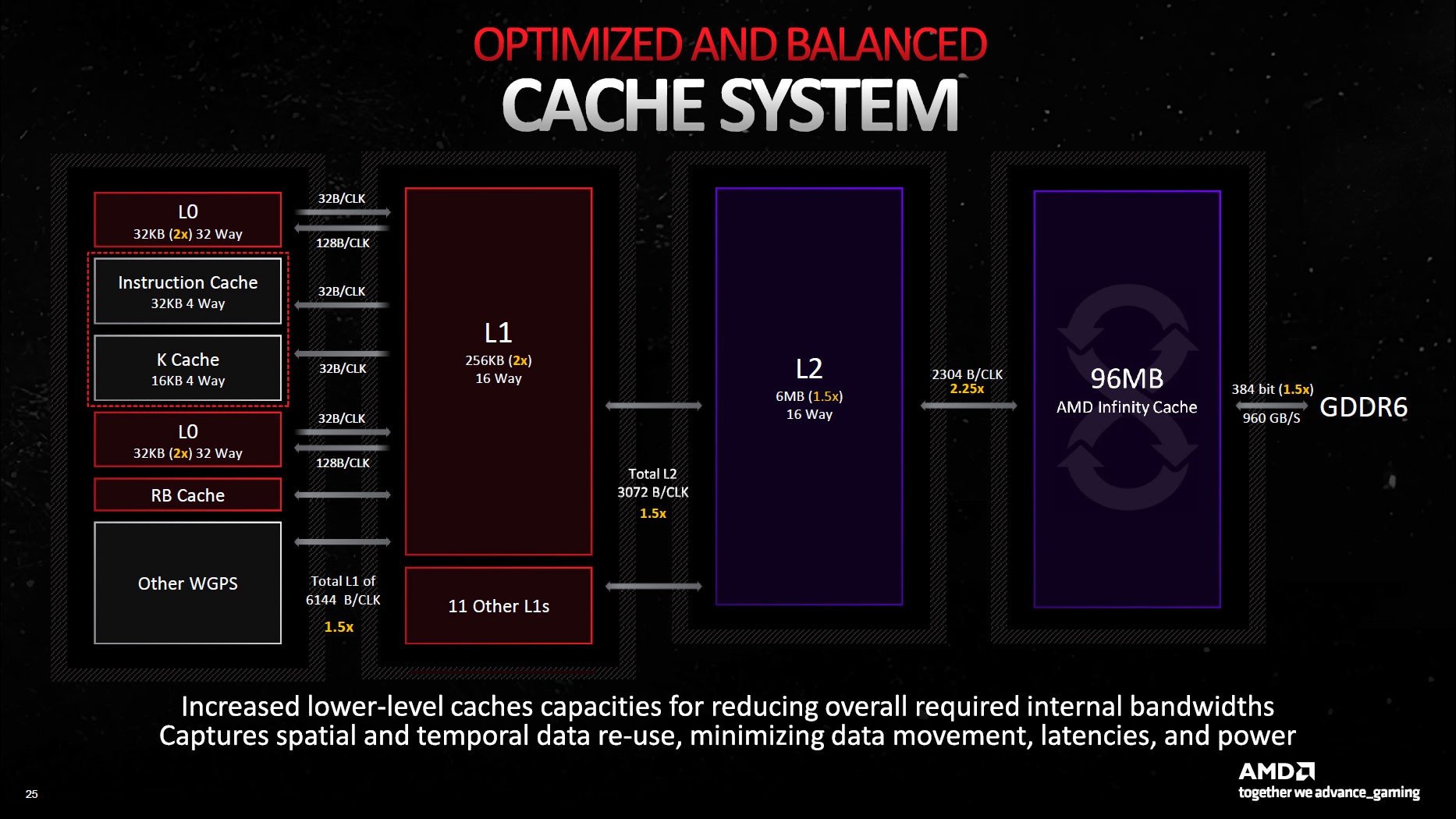
Son olarak, GDDR6 bellek yapılandırmasında toplam 384 bit temas için artık 6 adede kadar 64 bit GDDR6 arabirimi var. VRAM toplam 960 GB/sn’lik bant genişliğini ortaya çıkarırken 20 Gbps (RX 6×50 kartlarda 18 Gbps ve özgün RDNA 2 yongalarında 16 Gbps) suratında çalışıyor.
Başka bir noktaya parmak basacak olursak, GDDR6 ve GDDR6X ortasındaki fark da yeni kuşakla birlikte daraldı. 960 GB/sn bant genişliği sunan RX 7900 XTX, 1008 GB/sn bant genişliğine sahip RTX 4090’a çok yakın. RTX 3090 (936 GB/sn) ve RX 6900 XT’nin (512 GB/sn) ortasındaki fark ise çok daha fazlaydı.
2. Jenerasyon Ray Tracing (Işın İzleme)
Işın Hızlandırıcı (Ray Accelerator) üniteleri ikinci jenerasyona geçiş yapıyor. Bu ünitelerin sayısı tıpkı kalmış. Yani tıpkı RDNA 2 mimarisinde olduğu üzere, her Süreç Birimi’nde (Compute Unit) birer Ray Accelerator yer alıyor.

AMD RDNA 3 ışın izleme teknolojileri.
Kırmızı grup, çekirdeklerin ışın izleme senaryolarında 1.5 kat daha fazla ışın üretebilecek kapasiteye ulaştığını belirtiyor. Ayrıyeten GPU’ya ışın izlemeyle ilgili yeni komut setleri de eklenmiş. Her bir CU’da bir RA olduğunu söylemiştik. AMD’ye nazaran bu üniteler eskisine nazaran %50 daha performanslı.
Yapay Zeka Hızlandırıcı
Bildiğiniz üzere ekran kartları artık birçok alanda değerli rol oynuyor. AMD de her bir Süreç Birimi’ne iki adet Yapay Zeka Hızlandırıcı (AI Accelerator) dahil etmiş. Yapay zeka iş yüklerinde verimlilik artarken performansın 2.7 kata kadar arttığı tez edilmiş.

Ham süreç gücünden emin değiliz, lakin AI hızlandırıcıların hem INT8 hem de BF16 (brain-float 16-bit) süreçlerini desteklediğini biliyoruz. Yani muhtemelen NVIDIA’nın Tensor çekirdeklerine benzeri bir yapı var, lakin desteklenen toplam komut seti sayısı tıpkı değil. Ne olursa olsun, AMD yeni yapay zeka hızlandırıcılarının 2,7 kata kadar güzelleştirme sağladığını sav ediyor. Hızlandırıcı sayısının artması, daha fazla Hesaplama Ünitesi ve artan verimlilik bir ortaya gelerek bu performans artışını sağlıyor.
Diğer İyileştirmeler
Komut İşlemcisi (CP) güncellemeleri, makul iş yükleri için performansı artırırken şoför ve API tarafındaki CPU darboğazlarını da azaltacak. Donanım tabanlı ayıklama performansı da geometri tarafında %50 daha süratli ve saat başına en yüksek rasterleştirilmiş piksel sayısında %50 artış var.
Yeni mimariyle birlikte kullanıma sunulan Dual Media Engine, AMD’yi görüntü tarafında NVIDIA ve Intel ile birebir düzeye getirecek. Lakin kalite ve performansı görmek için ayrıntılı testler gerekli.

AMD ayrıyeten yeni RX 7000 ekran kartlarıyla DisplayPort 2.1 takviyesi sunmaya başlıyor. Intel de Arc GPU’larında DP2 takviyesi sunmuştu, fakat bu dayanak 40 Gbps (UHBR 10) ile sonluydu. AMD’nin irtibatı 54 Gbps (UHBR 13.5) sürate erişebiliyor.
AMD RDNA Mimarileri
|
RDNA
|
RDNA 2
|
RDNA 3
|
|
| Hesaplama Birimleri |  |
|
|
| Ray Tracing | |
2. nesil | |
| AMD Infinity Cache | |
2. nesil | |
| AI Acceleration (Yapay Zeka Hızlandırma) |
|
||
| AMD Radiance Display Engine | |
||
| Chiplet Tasarımı | |
| Ekran Kartı | RX 7900 XTX | RX 7900 XT | RX 6950 XT | RTX 4090 | RTX 4080 | RTX 3090 Ti |
|---|---|---|---|---|---|---|
| GPU | Navi 31 | Navi 31 | Navi 21 | AD102 | AD103 | GA102 |
| Üretim Teknolojisi | TSMC N5 + N6 | TSMC N5 + N6 | TSMC N7 | TSMC 4N | TSMC 4N | Samsung 8N |
| Transistörler | 58 milyar | 58 milyar | 26.8 milyar | 76.3 milyar | 45.9 milyar | 28.3 milyar |
| Kalıp Boyutu | 300 + 222 mm² | 300 + 185 mm² | 519 mm² | 608.4 mm² | 378.6 mm² | 628.4 mm² |
| SM / CU / Xe-Core | 96 | 84 | 80 | 128 | 76 | 84 |
| GPU Çekirdeği (Shader) | 6144 | 5376 | 5120 | 16384 | 9728 | 10752 |
| Tensor Çekirdeği |
– | – | – | 512 | 304 | 336 |
| Ray Tracing Çekirdeği |
96 | 84 | 80 | 128 | 76 | 84 |
| Boost Saati | 2500 MHz | 2400 MHz | 2310 MHz | 2520 MHz | 2505 MHz | 1860 MHz |
| Bellek Hızı | 20 Gbps | 20 Gbps | 18 Gbps | 21 Gbps | 22.4 Gbps | 21 Gbps |
| Bellek Kapasitesi | 24 GB GDDR6 | 20 GB GDDR6 | 16 GB GDDR6 | 24 GB GDDR6X | 16 GB GDDR6X | 24 GB GDDR6X |
| Bellek Data Yolu | 384-bit | 320-bit | 256-bit | 384-bit | 256-bit | 384-bit |
| L2 / Infinity Cache – Önbellek | 96 MB | 80 MB | 128 MB | 72 MB | 64 MB | 6 MB |
| ROP | 192 | 192 | 128 | 176 | 112 | 112 |
| TMU | 384 | 336 | 320 | 512 | 304 | 336 |
| TFLOPS FP32 | 56.5 | 43.0 | 23.7 | 82.6 | 48.7 | 40.0 |
| TFLOPS FP16 (FP8) | 113 | 86 | 47.4 | 661 (1321) | 390 (780) | 160 (320) |
| Bant Genişliği | 960 GBps | 800 GBps | 576 GBps | 1008 GBps | 717 GBps | 1008 GBps |
| Etkin Bant Genişliği | ? | 2900 GB/sn | 1728.2 GB/sn | 1664.2 GB/sn | – | – |
| TDP/TBP | 355W | 300W | 335W | 450W | 320W | 450W |
| Liste Fiyatı | 999$ | 899$ | 1099$ | 1599$ | 1199$ | 1999$ |